Best Practices for Bulk GraphQL Operations in Integrator.io
I'm looking for guidance on implementing bulk GraphQL queries and mutations efficiently in integrator.io, specifically regarding endpoint usage and workflow optimization.
Main Questions
1. Bulk GraphQL Processing Best Practices
What are the recommended approaches for handling bulk GraphQL queries and mutations in integrator.io?
2. Universal Shopify Connection Capabilities
Does the universal Shopify connection handle the complete bulk operation workflow automatically? Specifically:
Submitting bulk queries/mutations
Polling for completion status
Retrieving final results
3. Endpoint Usage Concerns
I'm concerned about endpoint capacity given our current constraints. Here's my understanding, if we are required to use async helper as the standard setup:
Current Workflow Requirements:
Bulk Query Results: Results are returned as JSONL files via https://storage.googleapis.com URLs
Bulk Mutations: Require uploading JSONL input files to AWS S3 via HTTP
Endpoint Impact:
If the universal Shopify connection doesn't abstract these operations, I believe we'd need:
Primary Shopify connection endpoint
Universal HTTP connector for Google Cloud Storage (result retrieval)
Universal HTTP connector for AWS S3 (input file uploads for bulkOperationRunMutation)
This would consume 3 endpoints total, and we're already at maximum capacity.
Specific Technical Questions:
Are there alternative approaches that would reduce endpoint usage?
If abstraction isn't available: Can we request additional endpoints at no additional cost to accommodate the bulk GraphQL workflow requirements?
Any insights or examples would be greatly appreciated!
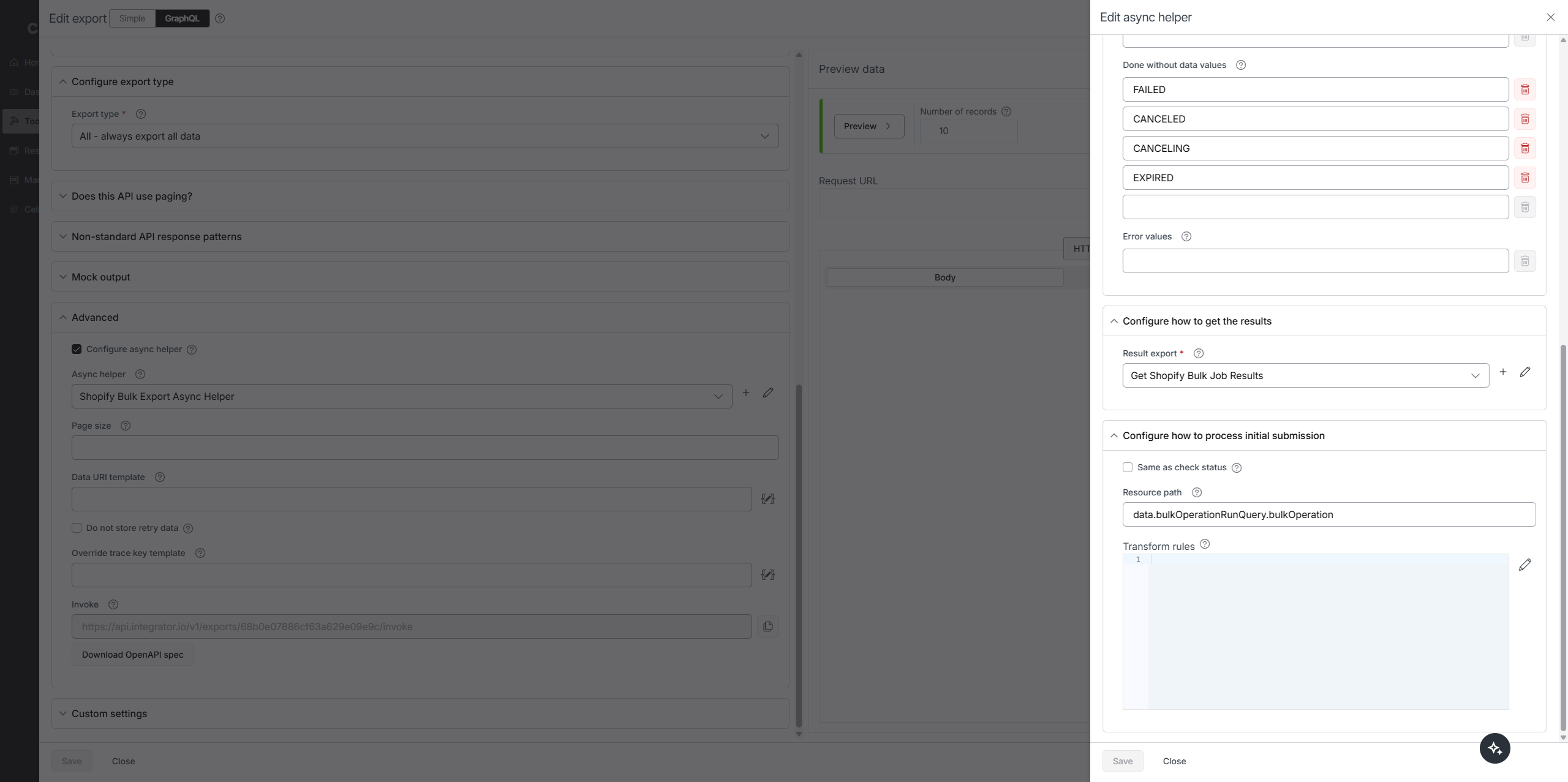
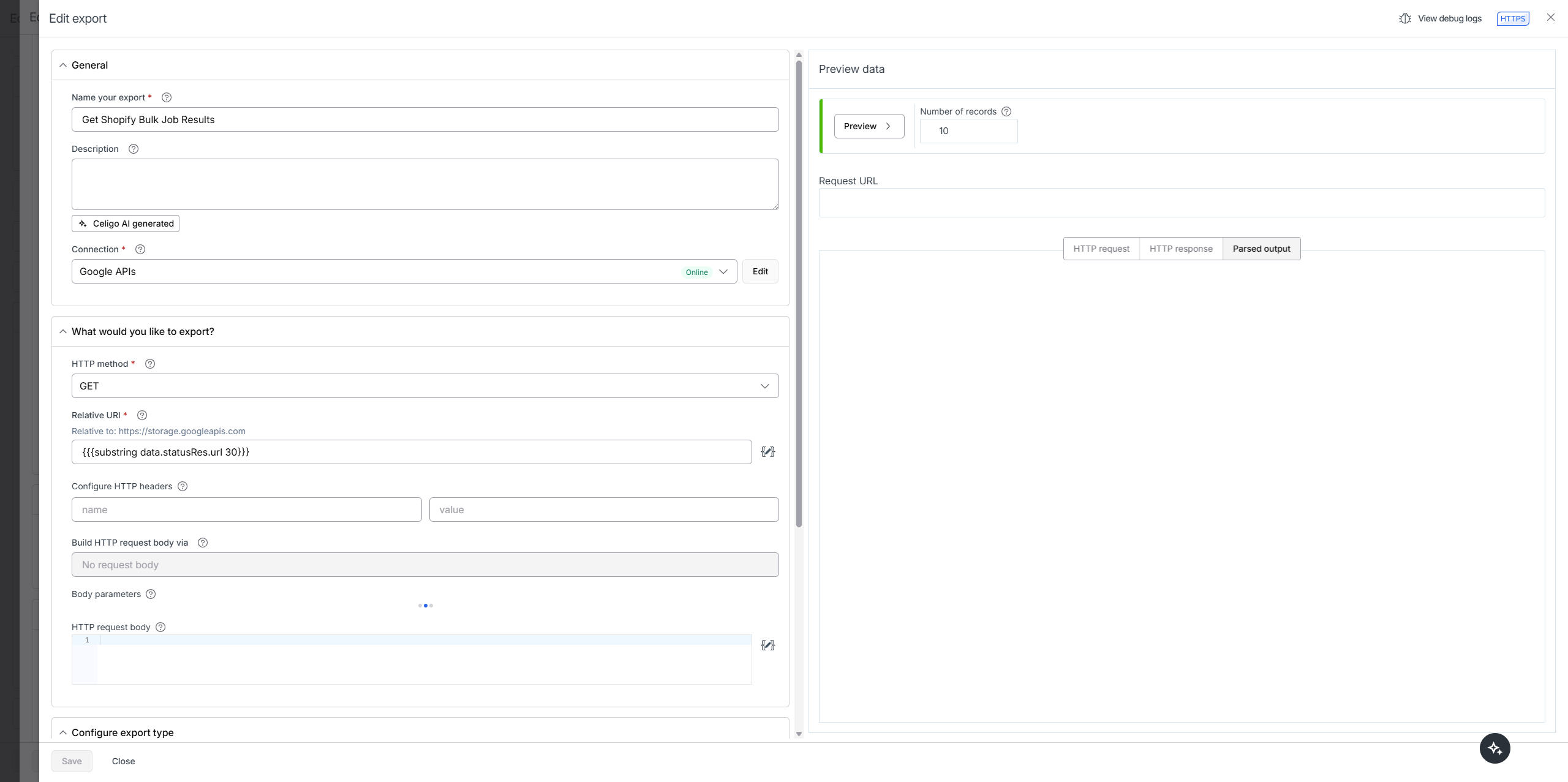
You can set this up with only 1 endpoint. You still create a Google APIs connection with no authentication, but since it is only used inside the async helper it does not count as an additional endpoint.
Prerequisites
Shopify GraphQL connection
Google APIs connection with no authentication (used by the async helper to fetch the JSONL results)
Step 1. Start the bulk job
Create an export with an async helper.
First request starts the bulk job.
mutation {
bulkOperationRunQuery(
query: """
{
products {
edges {
node {
id
title
}
}
}
}
"""
) {
bulkOperation { id status }
userErrors { field message }
}
}
I have followed the instructions, but when I switch onto the Google connection, it still prompts me that I have reached my maximum endpoints. See screenshot.