I need a way to guarantee idempotency in a webhook listener, such that calling the endpoint multiple times with the same record will result in duplicate records being ignored.
I was hoping to avoid having to query the destination system for duplicates, because there are multiple, and I'd rather not slow Celigo down checking each system on a pointless flow run.
The ideal would be if Celigo had some sort of built-in idempotency feature where it would discard duplicate requests, but I didn't see any options.
I was wondering if lookup caches would be suitable for this, using a flow like:
Webhook -> Query LC for record ID (abort if found) -> Add record ID to LC -> Proceed with flow
However, I wasn't sure if there would be some race condition two webhooks sent within X ms of each other would process concurrently, causing both to process fully.
Why would you have a source system send duplicate requests? I’ve seen a system send multiple requests for the same record, but there is typically some difference between the events, such as a different body field value or a different event type (in the community, a new topic makes both a new topic and a new post webhook request).
If multiple events are sent at the same time, the events will often get put into the same page of data, but that’s not guaranteed. So in this case, you could have a preSavePage script that removes the duplicates.
As you suggested, you could use a lookup cache as a holding location for events and then pull those events from the lookup cache and remove them after processing. The only problem I see there is how long do you wait to process events from the lookup cache? Would a duplicate event come in 10 minutes later? Even in this scenario, you’d need to use a preSavePage script to remove the duplicates, but you aren’t guaranteed to get everything on one page, so even that may not work. So you should set the page size higher so all unprocessed events get on one page. Ideally, you could use sort and group on the lookup cache export, but there is no sort option because we won’t fetch all results, store them in memory, then sort.
Given the above limitations, I would personally use a database to store the events and then you could use a SQL query to sort, rank, and filter. However, if your event volume is small and will always be small, I’d go the lookup cache route.
@friendoftuesday I was also discussing this with @tonycurcio offline. Lookup cache would be a good solution if your events were true duplicates. So if your flow was a simple webhook to upsert to lookup cache, then the second event upsert to lookup cache would override the first event upsert. Then you’d have a second flow that runs periodically to grab unprocessed records from lookup cache.
This is actually a flow that's been running successfully for months (thousands of records), and I only discovered this after a single duplicate was created this week — so the duplicates are definitely the exception. (We did also find a handful that had gone unnoticed previously.) That said, these are actual orders so that are being processed, so it is important to ensure that no duplicates get through, even rarely.
That actually wasn't how I was thinking, so I'm glad you clarified. I was thinking of doing the lookup cache insert/lookup inline in the same flow, but using two flows does remove the issue I was concerned about with parallel processing.
From what I saw, they all seemed to arrive essentially simultaneously. I didn't see any that were processed on separate pages.
This seems like the simplest solution; I am a little concerned that it might still let an order slip through, but all the duplicates that I could find came through on the same page.
The main downside to the two-flow lookup cache solution is that it will add a delay to what was previously a real-time flow. Not the end of the world if it's set to run every 15 minutes, but the team is used to being able to have orders appear immediately after being created, so that will likely cause a bit of frustration.
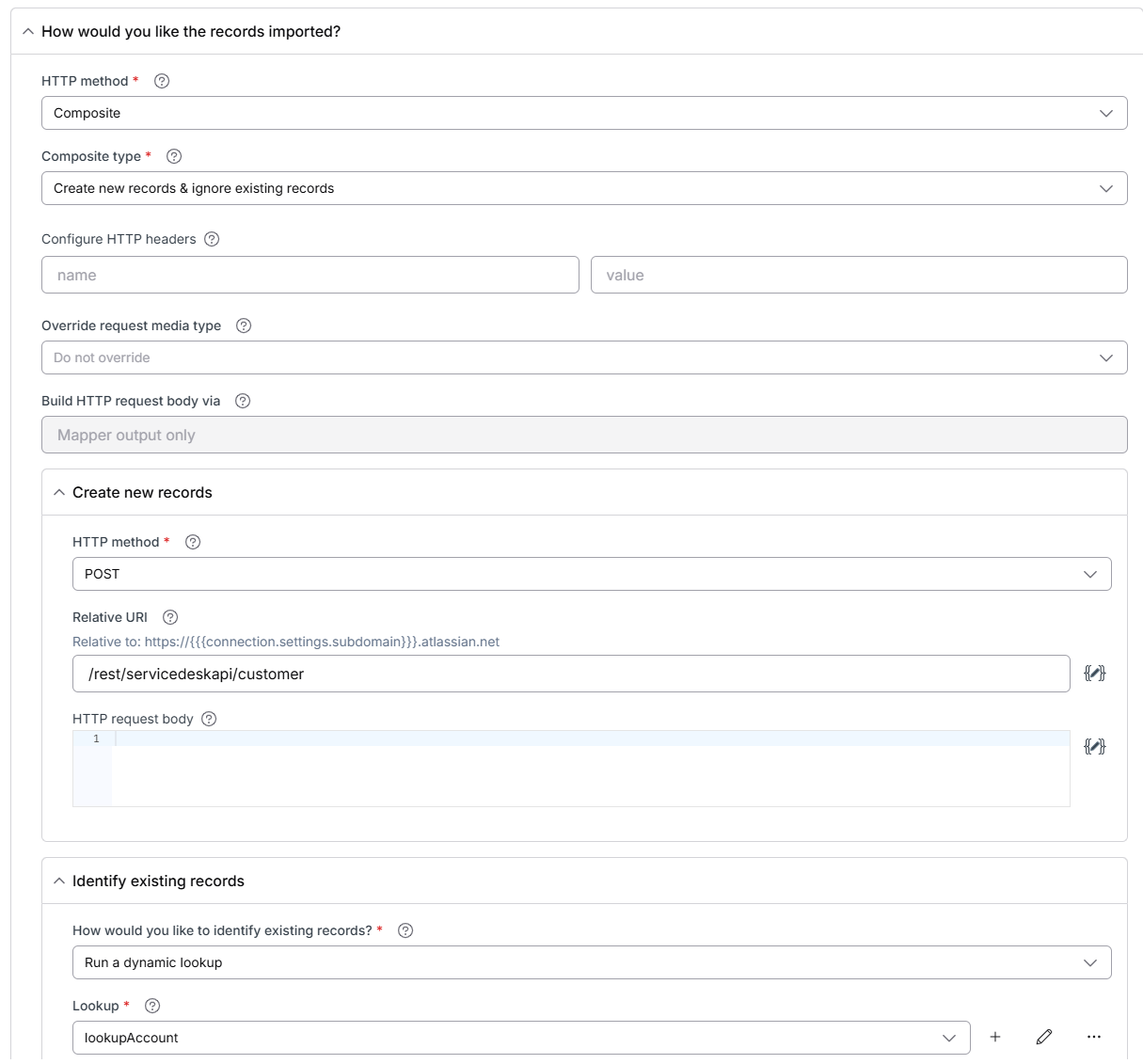
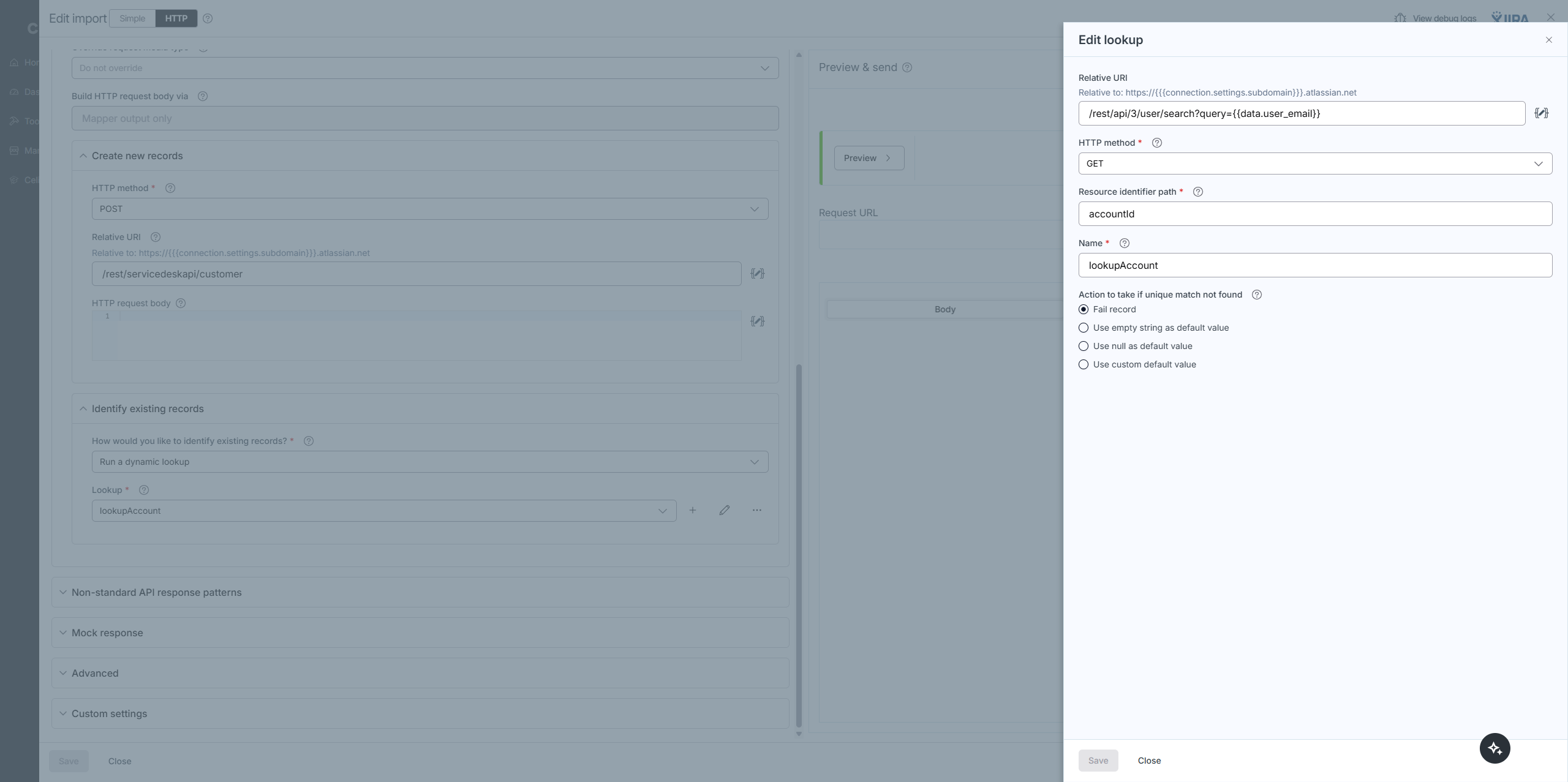
Alternatively, what system are you importing orders to? You could try using the composite API for your import and then not need to do anything with lookup cache. The composite API lets you do a lookup before making a create or update call. So you could make the lookup part of the composite API fetch against the destination system to see if it already exists there, and if so, you just ignore the record. For this, I would set the page size to 1 on the export (since the composite API does all lookups first, then does the update/create operation). You’d probably also need to set concurrency to 1 on your connection so that everything processes sequentially.
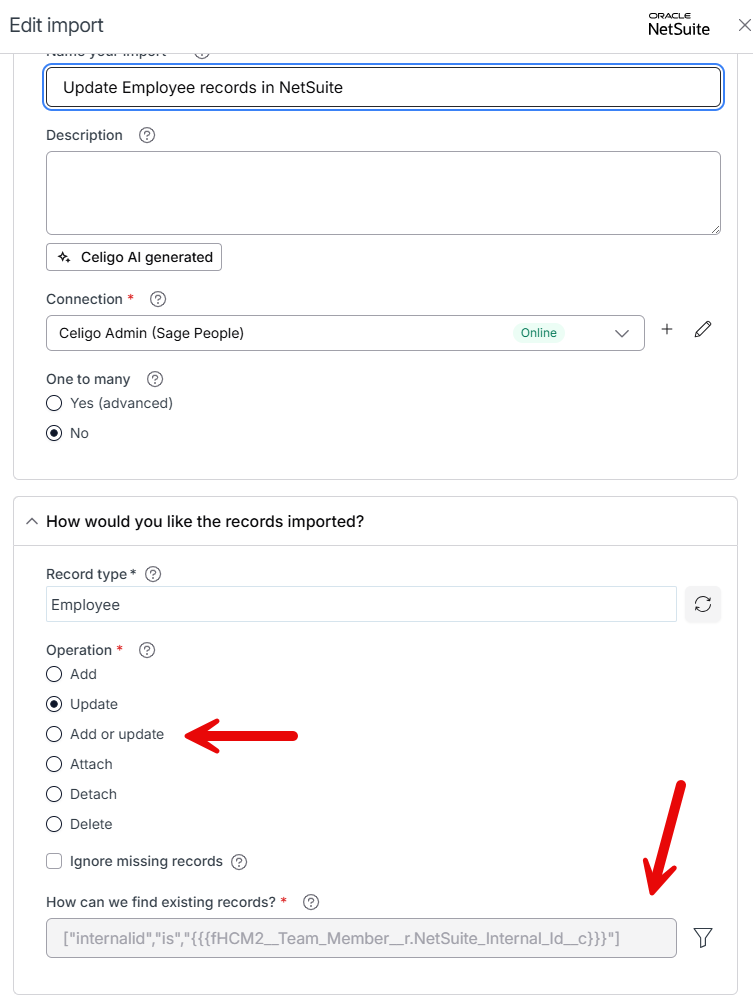
If you’re going to NetSuite or Salesforce, then those have built-in "how to find existing record" options on the import configuration.
That would definitely work. The main downside is that the flow is doing at least 4 imports across 3 systems, so this would result in duplicate logic across each import step — along with the potential that if/when an additional endpoint is added, people might forget/not realize they needed to have a lookup at each import.
Also, NetSuite is slow (sometimes <30s for a simple lookup). Lookup caches are basically instantaneous.
Actually, on second thought, if I have the first import step return fields for a response mapping, then I could just branch the flow to an empty branch after the first import step.
I think that beats the other options just by simplicity.